

Discover deeper insights, faster
Unlock business-wide insights from the data you depend on.
Xplore organizes and classifies data assets, and allows to search, access and collaborate in a data-driven environment.
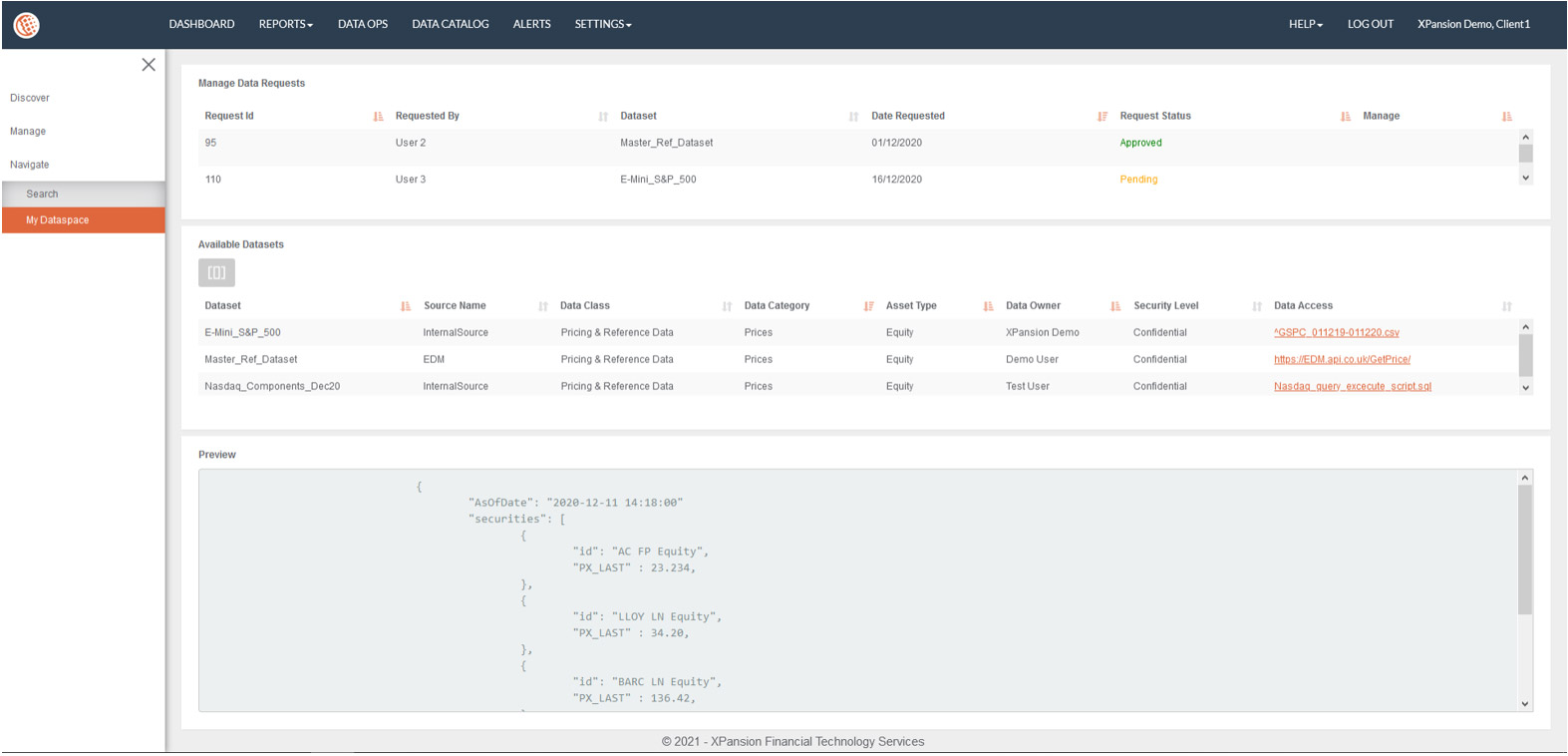
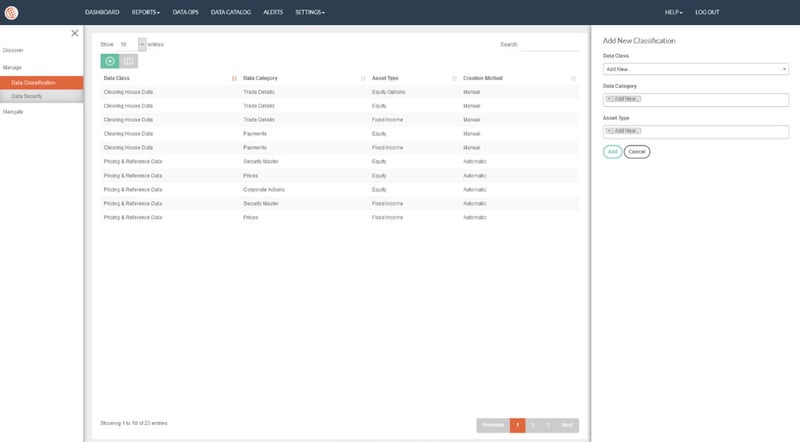

Xplore organizes and classifies data assets, and allows to search, access and collaborate in a data-driven environment.